Surfacing notes in my garden that have no claims
As mentioned in [[2024-02-17]], I want to make sure that I document at least the top two or three salient claims from every book and article that I read. Otherwise it seems like wasted effort.
So, here I'll think about how to surface information on this from org-roam.
So I'll try to tag book notes (and others, such as podcasts and article) such that I can run a query that pulls out those that I've read but have no associated claims.
To do so will be a positive act of [[knowledge commoning]].
I can get a list of all notes tagged as e.g. :book:read:.
select * from nodes where id in (select node_id from tags where tag = '"book"' intersect select node_id from tags where tag = '"read"');
Then I'd need to check all of their outbound links to see if any of them are claims.
To get all outbound links:
select * from links where source in (select node_id from tags where tag = '"book"' intersect select node_id from tags where tag = '"read"');
Hmm. I need a way to iterate through though.
Might be simpler to do it somewhat programming rather than trying to do it all in one shot via a gnarly SQL statement.
Options:
- do it in Metabase with models getting me each step of the way
- do it in org evaluating results along the way
- do it in something like Jupyter
Metabase
Pros
- Easy to set up and query the DB. I like it and use it at work. Good visualisation options.
Cons
- Needs to be running somewhere remote for me to access it from mobile.
- Perhaps a bit harder to do programmatic things like iteration etc.
Spike
So I want read books - easy, just filter by tags. Then I want to find those where there is no claims associated to it. So perhaps I can get all claims?
Easy if I base it on tags. But not all of my nodes are tagged, very few are in fact. Either I go through and tag them all, or try to pull it out of the content itself. That would be based on backlinks.
OK, I managed to do this pretty quickly.
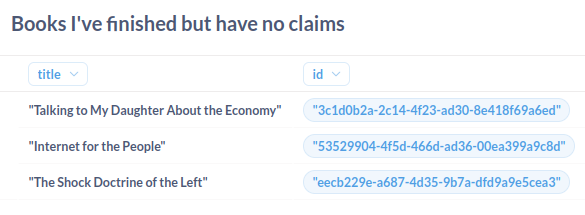
I made heavy (and possibly incorrect) usage of Metabase models.
I first made a 'Read books' model. Based on filetags, so currently incomplete.
Then a 'Claims' model. This one based on backlinks, as hardly any of my claims have filetags. Maybe I should do the same for 'Read books' and not worry about filetags?
Then a 'Nodes without claims' model.
Then 'Books I've finished but have no claims' is just a simple join between 'Read books' and 'Nodes without claims'.
Some thoughts along the way:
- I should decide whether to use inline links or filetags to denote certain types of node. Inline links is perhaps more 'pure' wikiing. But filetags will be a lot quicker to query I imagine.
- Making heavy use of Metabase models lets you build things up bit by bit.
- One big downside of this way - unless I set up Metabase on a server somewhere, I can only look at this stuff on my laptop. Which, at present, I'm not often at. Having everything built directly into org and published would mean I could have it as pages in my garden, always visible.
- Even if I didn't use Metabase for final output, I find it a handy rapid prototyping tool for querying org-roam.db.
Jupyter
Pros
- Workbook style
- Can combine SQL with code
- All the power of python
Cons
- Same as with Metabase, I'll need it running somewhere or exporting regularly if I want to see the results in my garden itself.
org babel
Pros
- Workbook style
- All contained within org
- Can easily publish it wherever I publish my garden
- Can view it on my mobile
Cons
- Performance, it'll be slower than the others.
- Bit more of an esoteric way of doing it?
If I can use a combo of SQL and code to iterate through results then we're good. I think I can?
I'll see if I can recreate the Metabase results from above at: [[Books I've finished but have no claims]]
Here's how I got there: [[Finding books without claims in org-roam using org-babel and sqlite]]
Useful resources
- public document at doc.anagora.org/surfacing-notes-in-my-garden-that-have-no-claims
- video call at meet.jit.si/surfacing-notes-in-my-garden-that-have-no-claims